La versión mayor mas vieja de Python acaba de ser “terminada”, al dejar de tener soporte oficial por parte de la PSF. Python 2.x no tendrá mas actualizaciones.
Desde hace tiempo ya la versión menor de Python se retuvo en 2.7, quedando en el aire la versión 2.8 que nunca vió la luz. Python 3, la versión mayor de Python ha estado entre nosotros desde 2008, 11 años le ha costado para poder ser la unica versión mayor de Python.
Y por que le tomó a Python cambiar por completo un total de 11 años?. Bien la cuestión es que Python 3.x no es compatible con Python 2.x, es decir, si escribes un programa pensando en la sintáxis de Python 2.x es muy probable que no funcione al correrlo con el interprete de Python 3.
La adopción de Python 3 entonces se retraso porque los desarrolladores de las principales librerias y apps tuvieron que empezar a soportar Python 3. El tener dos versiones de Python provocó que muchos desarrolladores ya metidos en Python continuaran con Python 2, las nuevas generaciones empezaron con Python 3 porque era lo mas nuevo, pero las generaciones que de por si usan Python se tomaron mas tiempo.
En mi opinión, depreciar por completo Python 2 está principalmente motivado a que muchos todavia usan Python 2 porque es simplemente mas cómodo continuar con el mecanismo que ha existido durante tanto tiempo en lugar de migrar. Dicho de otro modo, depreciar Python 2 es una forma de obligar a los desarrolladores a usar Python 3.
¿Tu por que crees que Python 2 aguantó tanto (11 años) en ser depreciado?
Este es un “re-post” en español de este otro articulo que escribí en inglés: Python trick: How to make lazy objects?. Si ya leíste aquel articulo igual te invito a que leas este, compares y compartas.
Esta vez voy a hablar de los “lazy objects”, los he llamado así porque son mas o menos similar a lo que usaba con los “Lazy treeviews” en GTK donde el árbol muestra los expansiones pero no se cargan los nodos hijos hasta que expandes el nodo. Lo que quiero entonces es crear objetos que sirvan para contar, que tengan un tipo de dato, pero que no carguen nada de datos hasta que se necesite.
¿Por que haría esto?, bueno, actualmente estoy trabajando en un programa que muestra una lista de clientes y muestra cuántas cuentas tiene, estas cuentas son algo complejas así como crear el objeto para representarlas. Este objeto es responsable de cargar y guardar datos, y cualquier dato necesario es accesado via “propiedades”.
En mi primer intento, el objeto cargaba con los datos tan pronto como el constructor era llamado, pero a veces nunca accedía a la información en dicho objeto, recuerden, un client puede tener muchas (y me refiero, muchas muchas) cuentas, entonces, ¿por que cargar todos los datos si hay una oportunidad de que nunca voy a usar ese dato?. Bueno, está ahí por qué también hay una oportunidad de que voy a necesitar ese dato.
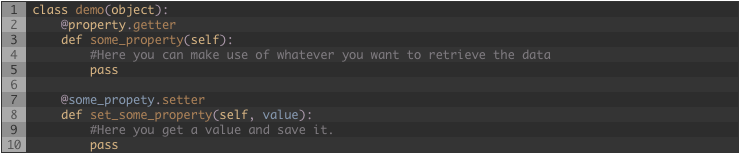
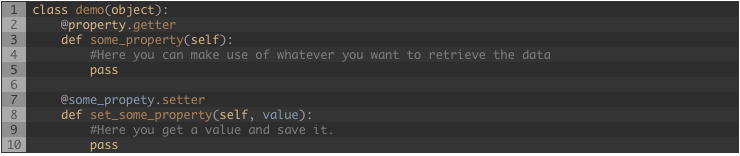
Entonces, como podría crear un objeto y despues cargar los datos cuando alguien los requiera?. Eso podría ser fácil… tal vez no ?. Una aproximación es hacer uso de las “propiedades” de Python, crear el objeto y cuando alguien necesite un valor de este objeto entonces usar la propiedad para obtener el dato, procesarlo y retornar un valor, una propiedad se puede definir así:
He creadola clase “demo” y la propiedad “some_property”.
Python va a llamar el método get_some_property permitiéndote hacer el truco. Pero si tienes un objeto con mas y mas propiedades es mejor obtener todos los datos de una vez y solo usar propiedades para regresar un pedazo de el. Podrías llamar a un método en cada propiedad si el contenedor está vacío pero para mi no es lo mejor.
Lo que podemos hacer, es obtener los datos la primera vez que los necesites, pero como sabría que datos/variables son requeridas en mi objeto?.
Bueno, pues las clases de Python tienen ciertos métodos, los llamados “magic methods”, uno de ellos es __getattribute__. Este método te permite manejar cada petición a cualquier propiedad o variable de clase en tu objeto.
Con esto puedes buscar en tu objeto, saber si el contenedor esta vacío y si está vacío entonces llenarlo con datos antes de retornar el valor de la propiedad ?
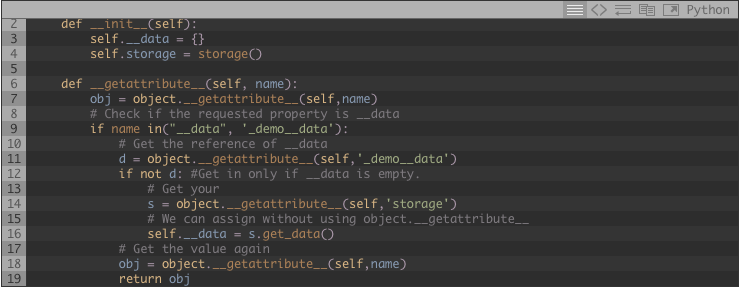
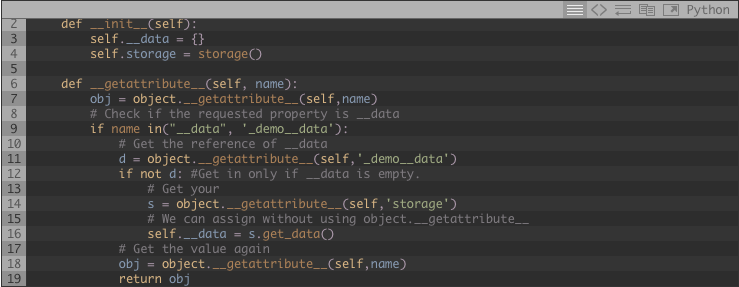
Digamos que el objeto demo tiene un diccionario llamado __data donde almacenaremos la información necesaria, también tenemos propiedades que buscarán por esta información. también tiene una referencia a la capa de almacenamiento.
Presta atención que he usado object.__getattribute__ en lugar de self.property, si usara self.propertyesto llamaría a self.__getattribute__ y esto causaría una excepción de recursión.
Con eso, podemos crear un gran numero de objetos de forma rápida, al mismo tiempo que reducimos el uso de memoria. La paga es que obtener los datos será mas caro si llegaremos a requerir todos los datos de todos los objetos al mismo tiempo.
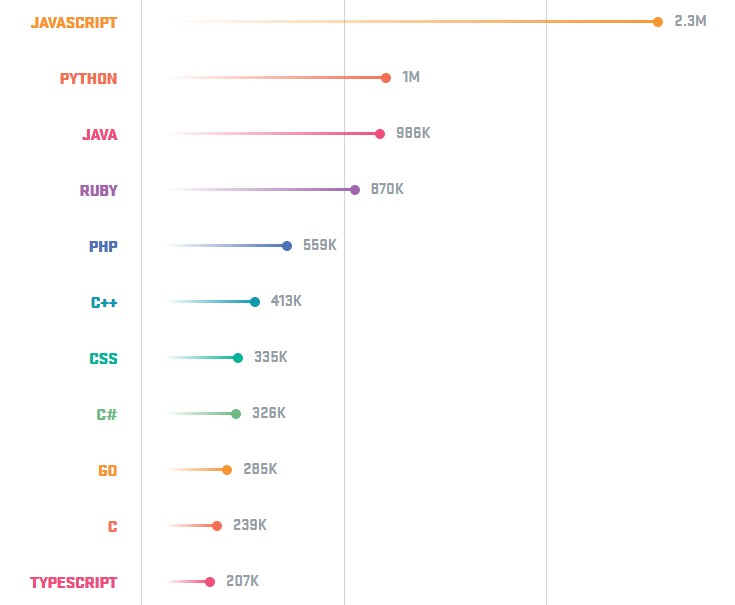
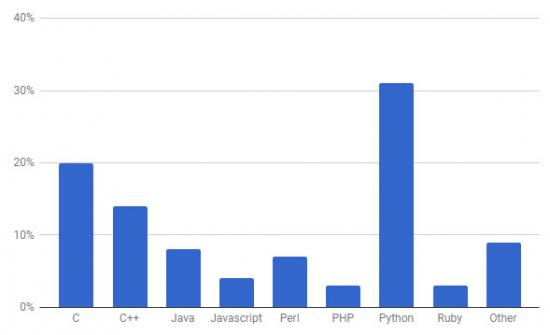
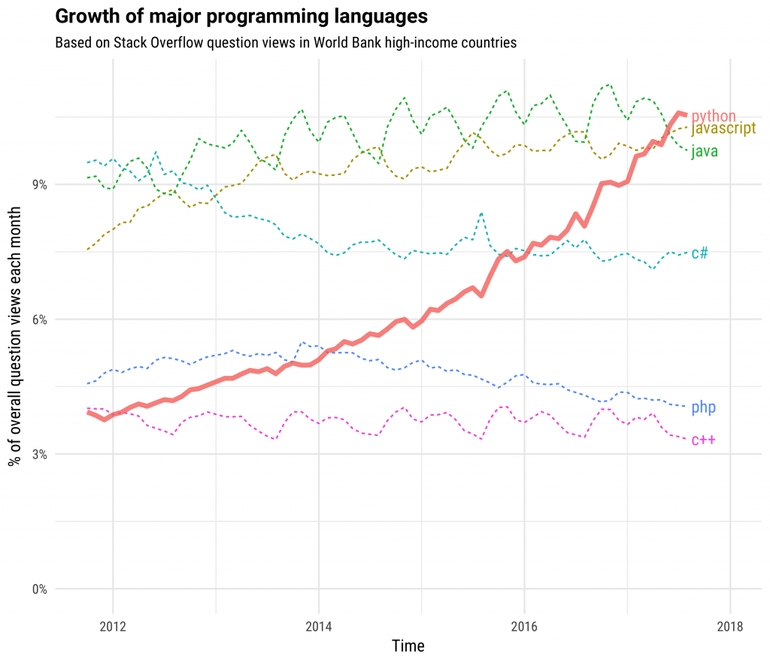
La cuestión es que JavaScript está presente como bien dice el articulo, en cerca del 95% de los sitios web en el mundo, es un lenguaje de programación que domina la forma en la que las paginas web tienen cierto dinamismo, vaya, para nadie es raro escuchar de la tripleta HTML5+CSS+JavaScript, sin embargo otras tecnologias como Flash o Java decayeron tanto que solo un par de navegadores lo soportan aún.
Python por otro lado es un lenguaje de uso general, muy popular en el backend y en aplicaciones de Machine Learning y computo científico, es su sencillez y madurez lo que le da su popularidad, sin embargo no cuenta con esa exclusividad que tiene JavaScript.
Es JavaScript un mejor lenguaje que Python?. Lo dudo mucho, hay muchos ejemplos de lo que está roto en JavaScript, tanto que hasta juegos sobre sus patrones de igualdad hay. Incluso hay lenguajes que se compilan a JavaScript para hacer las cosas mas “sencillas” y menos susceptibles a errores. Sin embargo, como dije en el párrafo anterior, JavaScript cuenta con esa exclusividad en la web que hace casi imposible que otro lenguaje de programación sea tan popular como él. Si vas a aprender a hacer sitios web tienes por fuerza que aprender a usar JavaScript, incluso si usas algún framework. Otro punto fuerte de JavaScript son los dispositivos móviles, para muchos el tener que mantener la misma app en diferentes plataformas los ha llevado a tener un framework con un lenguaje de programación común, ahí es donde JS ha sido el que ha triunfado, es común encontrarse frameworks que usan JS y “convierten” estas instrucciones a una app nativa, o en el peor de los casos a una especie de web-view con el dinamismo dado por JS.
Como podría Python ganarle terreno a JavaScript?, lo está haciendo muy bien sirviendo desde el backend (como de costumbre), muchos sitios web estan construidos sobre Django, APIs que se han construido sobre Flask, en el computo científico es muy pero muy popular, pero seria genial que Python fuera la base para alguna plataforma móvil, te imaginas escribir apps para dispositivos móviles usando Python de forma nativa? es decir, que el dispositivo use Python directamente, que no se compile a JS, Java/Kotlin u ObjectiveC/Swift.
Cuál es tu predicción a 5 años?, Python será mas popular que JavaScript?.
JavaScript and Python are two influential programming languages for building a wide range of applications.
Guido van Rossum hizo el merge del PR de Victor Stinner, por lo que los términos Master y Slave ya no aparecerán en la versión 3.8 de Python, aunque uno de los PRs quedó fue porque refleja la terminología de las pseudoterminales de UNIX.
Así que váyanse preparando, para eliminar los “child processes” porque como vas a tener a un niño trabajando. Igual los Daemons, y finger tendrá que ser renombrado porque, pues propone un dedo y no se me vayan a ofender por eso…
A ver que opina usted, ¿le gustaría que se dejaran de usar los términos “master” y “slave” o “Maestro” y “Esclavo” de la terminología en Python?.
En lo personal creo que hay muchas cosas mejores que hacer, un par de palabras que no me parecen en absoluto ofensivas porque desde un principio, no estan dirigidas a mi, no se refieren a mi, de hecho, no se refieren a una persona, se refieren a un par de procesos.
Me da un poco de coraje mezclado con tristeza el hecho de que haya personas que con cosas tan triviales como un par de palabras se sientan ofendidas, deberían entender que son solo palabras, las palabras sin contexto no tienen un verdadero significado y dentro del contexto en Python solo se refiere a un proceso que tiene el control sobre otro que no, lo que dice que no es el maestro y el otro el esclavo.
Considerando esto, cualquier palabra podría en algún momento ser ofensiva si nos ponemos a pensar en casos de uso, algo como perro podría ser ofensivo, porque a alguien tal vez le dijeron perro. Al rato va a resultar que no quieren que se diga “Camel Case” porque.. bueno, los camellos pueden sentirse ofendidos.
Usted que opina?
The political correctness debate has now found its way to the world of computers, after a developer from the Python programming language suggested that the words “master” and “slave” should be removed.
En un post anterior les comenté las buenas prácticas en Python, ahora toca hablar de Django, si bien Django esta hecho en el lenguaje Python tiene sus propias convenciones como framework, y seguir estos lineamientos permitirá que tengas proyectos organizados pero sobre todo, que tus compañeros de trabajo (si todos siguen estas recomendaciones) y tu funcionen mejor.
Estilo de código
Aquí no hay mucho que decir, estamos hablando de Python y por lo tanto aplican las reglas de estilo de Código de Python, debes escribir siguiendo la PEP8. Django también tiene sus propias convenciones para escribir código, estas las puedes encontrar aquí , coteja con las de Python, verás que son complementarias.
Settings
settings.py es uno de los módulos principales en tu app, en el se definen los parámetros con los que ha de funcionar tu aplicación, es importante mantener limpio este módulo, e incluso, quitar lo que no es básico para entender el funcionamiento de la aplicación o moverlo a otro lado.
Recordemos que estamos hablando de Python, podemos hacer nuestro settings.py muy modular, e importar lo que se necesita en el momento. Por ejemplo, las configuraciones de logging , o las configuraciones correspondientes al ambiente de desarrollo que son típicamente diferentes a las de producción.
Rutas
Nuestro ambiente de desarrollo esta en una ruta en el almacenamiento diferente de la que estará en producción, es por ello que debemos evitar usar rutas “duras”, en su lugar debemos referirnos a rutas relativas a una que Python nos proporcionará.
Es común ver en el settings.py la variable BASE_DIR y STATIC_ROOT que son variables donde se define la ruta absoluta del proyecto en disco duro, así como donde se guardan los archivos estáticos en disco duro. Estas variables las podemos definir mejor así:
En nuestro proyecto veremos un archivo urls.py que no es mas que un módulo que contiene la información de cada una e las URLs dentro de nuestro proyecto. Me ha tocado ver urls.py tan largos como la cuaresma, y no, no es nada bonito tener un módulo asi de grande, sobre todo porque es confuso.
Que podemos hacer entonces?. Bueno, en principio, tener un urls.py en cada app de tu proyecto, de esta forma cada app será independiente, se reducirá el tamaño del archivo principal y te será m as fácil ubicar las urls en caso de agregar/editar/borrar. La otra, en el caso de que nuestra app tenga muchas urls, es modularizar, puedes repartir las urls en mas módulos dependiendo de cada sección dentro de tu app.
Plantillas
Las plantillas en Django están en básicamente en dos lugares, en el directorio base de tu proyecto y en el de cada app, ahí deberá haber un directorio llamado templates. Lo importante aquí es que las plantillas de tu app deben estar en el directorio templates dentro de tu app. Las plantillas “base” o genéricas podrían estar en tu directorio templates en el directorio base.
Lo mismo que con las plantillas. Cada app debe mantener su contenido estático para cada una de ellas, con esto mantienes la independencia de la app y permites que pueda ser usada en otros proyectos.
El contenido estático pueden ser:
imágenes
JavaScript
CSS
Ojo, no se debe confundir el contenido estático con el contenido que sube el usuario final, este contenido que sube el usuario va al directorio “Media”
Otras convenciones que aplico yo
Estas no están dentro de las convenciones de las buenas prácticas en Django, pero las he usado y me han servido muy bien:
Convertir views.py /forms.py en un paquete
Con esto puedo seccionar las partes de mi app, así tengo Views para cada sección y son generalmente archivos pequeños. Con esto evito tener un “views” de mas de 1000 lineas.
Django desde hace buen tiempo ya cuenta con las Class Views. Antes estábamos acostumbrados a que cada vista era una función, pero los Class Views tienen muchas ventajas sobre las funciones.
Lo que mas me gusta es que puedo crear una clase base y solo extender su uso dependiendo de la sección, por ejemplo, tengo la sección Customers, entonces creo una vista básica de “customers”:
class CustomerBasicView(LoginRequiredMixin ,TemplateView):
template_name = "blank.html"
# Esta variable de clase se llenará con el valor delcliente en turno.
customer = None
def get_context_data(self, *args, **kwargs):
# Crear el contexto y llenar lo "General"
def get(self, request, *args, **kwargs):
# Llamar get_context_data
# Llamar una función en las clases hijas para complementar el contexto
# Ejecutar una función anexa a "get" para finalizar get
# Si no existe dicha función retrnar
return self.render_to_response(self.context)
Y las demás clases solo necesitan heredar de CustomerBasicView
class Dashboard(CustomerBasicView):
template_name="customers/dashboard.html"
class View(CustomerBasicVIew):
template_name="customers/view.html"
class Edit(CusotmerBasicView):
template_name="customers/edit.html"
Como ven?. Dejaré una explicación mas detallada de esto que hago para otro post. Tal vez mañana.
Si te gustó el articulo, compartelo en tus redes sociales, si tienes algo que agregar con toda confianza hazlo en los comentarios.
Si hemos usado Django seguro nos hemos enamorado de su forma de hacer formularios, sobre todo los que están relacionados con un modelo, puesto que son simplísimos. Hay que reconocer lo simple de Django, y gracias a esta simplicidad que no busca satisfacer completamente todas las necesidades podemos encontrarnos con situaciones que pues, no se apegan a lo que queremos hacer.
Programar es divertido, sobre todo si tienes a tus manos el lenguaje de programación y otras herramientas de tu elección, sin embargo, a veces cometemos errores que bien fácil podemos evitar si seguimos estas buenas prácticas.
Python, continua con su desarrollo y aunque en la versión 2.7 ya no tiene grandes cambios si que lo tiene en la versión 3, en esta ocasión la versión 3.7 que incluye una cuantas cositas que si que valen la pena mencionar.
Microsoft, a company that have their very own tools and programming languages is now making it easier for developers to use their favorite language. This time Python have better support in the Visual Studio Code, more specifically in the IntelliSense autocomplete System.
Visual Studio Code is the source code editor that Microsoft released as Open Source and is available in Linux, Windows and MacOS. and thanks to the Python Language Server now have better support for Python. I mean, Python support has been there for a while, but is greatly improved by the PLS.
Do you use Python or Visual Studio?, leave your thoughts in the comment section.
Python Language Server an option for those that code
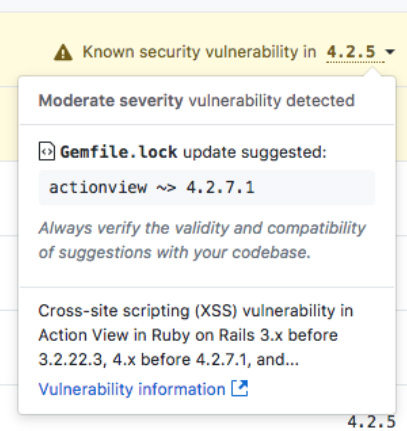
This is good, as a developer is a PITA to follow all the dependencies your app have. There are several tools to keep them up to date (updating your requirements.txt file) for future builds/updates of your app. But sometimes we just don’t follow the security flaws.
GitHub’s Security Alerts now also work for Python projects, notifying developers about vulnerabilities in software packages that their projects depend on.
Not that I’m surprised, Python is in humble opinion the best balanced programming language, it is really general purpose pl doing from simple automation scripts to complex projects and scientific computing.
I started to use vagrant to hold my development environment, it helps to keep the development environment isolated, since the app will run on a Linux server, with a specific database engine and probably some other specific modules, I don’t want to clutter my OS with all that stuff. More if I plan to work on another project that maybe, have a dependency on other versions of the same base (legacy Django perhaps?)
A few weeks ago, I have to write a program in PyGTK that was supposed to be all the time in the background. This application needs to run over Microsoft Windows, and hide in the notification area, wich in Windows is near to the clock.
One of challenges for me in this application is that as it must run in the background there must be a way to raise it, the most easy way to do it is by force the user to click on the small icon in the notification area, but in this case, that was impossible because the computer don’t have any mouse, everything is done with the keyboard.
Python have several modules that help you to achieve your goals. This week, on my spare time that is getting every day more scarce I spend time figuring out how to create a Python Web Server, I was planing to use it over an application that I’m developing on ICT Consulting. At the end I didn’t use it because I didn’t want a “passive” communication, but probably I will use this code on the CRM Desktop application that we use here.
Anyway, this code may be helpful for you too. I found that creating a small web server is really simple, It starts getting bigger as you add functions to that web server, but the basis is quite simple.
import os
import cgi
import sys
from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler
class customHTTPServer(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write('<HTML><body>Get!</body></HTML>')
return
def do_POST(self):
global rootnode
ctype,pdict = cgi.parse_header(self.headers.getheader('Content-type'))
if ctype == 'multipart/form-data':
query = cgi.parse_multipart(self.rfile, pdict)
self.send_response(301)
self.end_headers()
self.wfile.write('Post!')
def main():
try:
server = HTTPServer(('',8080),customHTTPServer)
print 'server started at port 8080'
server.serve_forever()
except KeyboardInterrupt:
server.socket.close()
if __name__=='__main__':
main()
There are two main methods in our small server: do_GET and do_POST, you can figure out what this methods do. Get is quite simple, Post is used to send data to the server, as an example, the file uploading. This is done via POST and many times using “multipat/form-data” as the content type. The Post method here handles that.
Now that you have a custom server, how can you check it?, well, to check GET you can call it from the web browser. For the POST stuff, you can create a simple web form and using your web browser as “action” on it. However, this code can help you:
import urllib2
import urllib
import time
import httplib, mimetypes
HOST = '127.0.0.1'
PORT = '8080'
def post_multipart(host, port, selector, fields, files):
"""
Post fields and files to an http host as multipart/form-data.
fields is a sequence of (name, value) elements for regular form fields.
files is a sequence of (name, filename, value) elements for data to be uploaded as files
Return the server's response page.
"""
content_type, body = encode_multipart_formdata(fields, files)
h = httplib.HTTP(host, port)
h.putrequest('POST', '/cgi-bin/query')
h.putheader('content-type', content_type)
h.putheader('content-length', str(len(body)))
h.endheaders()
h.send(body)
#errcode, errmsg, headers = h.getreply()
h.getreply()
return h.file.read()
def encode_multipart_formdata(fields, files):
"""
fields is a sequence of (name, value) elements for regular form fields.
files is a sequence of (name, filename, value) elements for data to be uploaded as files
Return (content_type, body) ready for httplib.HTTP instance
"""
BOUNDARY = '----------ThIs_Is_tHe_bouNdaRY_
Did you like this?, don't forget to share!
CRLF = '\r\n'
L = []
if fields:
for (key, value) in fields:
L.append('--' + BOUNDARY)
L.append('Content-Disposition: form-data; name="%s"' % key)
L.append('')
L.append(value)
if files:
for (key, filename, value) in files:
L.append('--' + BOUNDARY)
L.append('Content-Disposition: form-data; name="%s"; filename="%s"' % (key, filename))
L.append('Content-Type: %s' % get_content_type(filename))
L.append('')
L.append(value)
L.append('--' + BOUNDARY + '--')
L.append('')
body = CRLF.join(L)
content_type = 'multipart/form-data; boundary=%s' % BOUNDARY
return content_type, body
def get_content_type(filename):
return mimetypes.guess_type(filename)[0] or 'application/octet-stream'
def test():
print post_multipart(HOST, PORT, 'markuz',
( ('username','markuz'), ('another_field','another value')),
(('query','query','Query'), ),
)
if __name__ == '__main__':
test()
This time I’m going to talk about putting an image as the application background in Gtk. In Gtk we are used to leave the colors of the application to the theme, but sometimes we will need to use an image as background. I already wrote how to draw a pixbuf in a gtk.DrawingArea (Esp), we could use that, but we will “draw” directly on the widget window instead.
Yes, I said the widget’s window instead the widget itself. You should know that every widget that has been packed in a container has a gtk.gdk.window object and is the responsible for containing your widget. Well, we can draw on that object.
What we need is to create a simple gtk.gdk.Pixbuf and call the gtk.gdk.window.draw_pixbuf method using your widget.window object on the expose-event.
It is just a window with an HBoxButton as container and a Button in the middle. The button draws normal, but the HButtonBox is drawing its gtk.gdk.window with a pixbuf.
This time I’m about to talk about lazy object, I called like that because they are more or less similar to what we use in lazy treeviews (In Gtk) where the Tree shows expanders but didn’t load the child nodes until you expand the node). What I want to do is create objects and count them, but don’t load any data until I need it.
Why would I need this?. Well. I’m currently writing a program for my employer, this program load a list of customers and shows how many accounts it has. As this accounts are kind of complex I create an object for them. This object is responsible for load/save the data for it, and any data you need is accessed via properties.
In my first approach, the object was loading the data as soon as the constructor was called, but sometimes I never access to any info in that object, remember, a customer may have many (and I mean really many) accounts, then why load all the data if there is a chance that I’ll never use it?. Well, that is because there is a chance that I have to use that data.
Then how could I create the object and then load the data when somebody require it?. That may be easy, may not. :-). One approach is making use of python properties. Just create the object and when someone want to use a “value” from the object use the property to retrieve the data, process it and then return a value. A simple property may be defined like this:
I just create a class “demo” and the property “some_property”, every time you use this:
Python will call the method get_some_property allowing you to do your trick. But if you have an object with more and more properties is better to get all data at one time and then just use properties to return a piece of it. You could call a method on every property if the data container is empty but for me it is not the best.
What you could do, is get the data the first time you need it. But, how could I know when a property/variable is requested on my object?
Well, Python classes have several reserved methods, and one of them is __getattribute__. This method let you handle every request to any property/class variable in your object.
With this you can dig in your object to know if the container is empty, and if it is empty fill it with data before returning the property value :-).
Lets say that the demo object have a __data dictionary containing the data. and propeties look into it for the right value, it also have a reference to the storage layer called storage.
Pay attention that I used object.__getattribute__ instead self.property, if I use self.property it will call self.__getattribute__ and will cause a recursion exception.
With this, we can create a great number of objects quickly and reducing the memory footprint. The downside is that getting the data will be a lot expensive if we require the data of all (or several) objects at once.
How would you do it?, let me know in the comments.
The last couple of days I’ve been working with Kivy. For those that don’t know is a framework to create applications in graphical environments and in multiple platforms, all of these in the most easy to use programming language: Python, (And I mean programming language, JavaScript doesn’t count).
Well, its interesting to work with it, basically because I have the influence of GTK+ and having no windows but calling to widgets creates some confusion. Also, there is this Kivy language which is something like what Glade is In GTK but a lot easier to read (actually everything is easier to to read than XML).
I’m just starting to do this, this post is not a “how to do things in Kivy”, but I hope I can write some of those in the next weeks.